J-LIWC2015チュートリアル・ワークショップ(日本心理学会第85回大会)
2024/11/6 RとJ-LIWC2015によるテキスト解析のページを更新しました。jliwcパッケージの公開により、WindowsのRでも分析が可能となりました。また、設定の手順が大幅に簡略化され、MeCabや他のRパッケージのインストールが不要となりました。
2022/4/8 RとJ-LIWC2015によるテキスト解析 のページを公開しました。
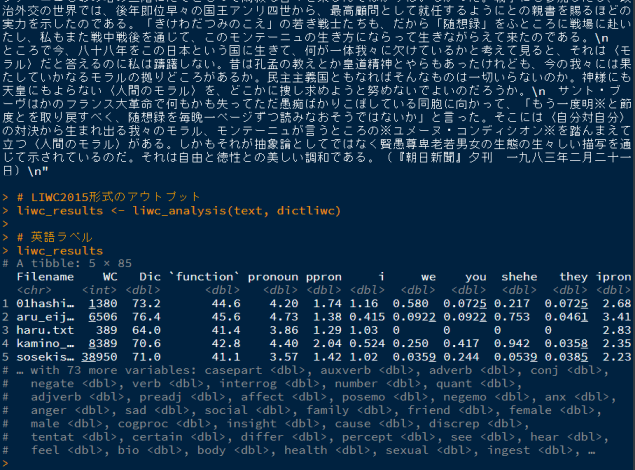
Rによる分析の手順はこのページを参照してください。
2022/3/7 論文が公開されました。
Igarashi, T., Okuda, S., & Sasahara, K. (2022). Development of the Japanese Version of the Linguistic Inquiry and Word Count Dictionary 2015. Frontiers in Psychology, 13:841534. https://doi.org/10.3389/fpsyg.2022.841534
2021/9/6 ワークショップの動画とスライドをアップしました。
ワークショップで用いたPythonスクリプトは、GitHubリポジトリからアクセス可能です。
※2021/9/3 辞書ファイルがダウンロード可能です(要:英語版LIWC2015のシリアル番号)。
日本心理学会第85回大会(オンライン)で、J-LIWC2015(日本語版LIWC2015)のチュートリアル・ワークショップを開催します。
日時:2021年9月2日(木)9:30-11:30(Zoomによるライブ配信)
セッション番号:TWS-003
セッション名:J-LIWC2015による日本語テキスト解析
講演者:五十嵐 祐(名古屋大学)、笹原 和俊(東京工業大学)、奥田 慎平(名古屋大学)
セッションURL:https://confit.atlas.jp/guide/event/jpa2021/session/2Live-A01-01/tables?nRlvUneqtE(要ログイン)
要旨:計算社会科学の領域において、デジタル化された文字情報(テキストデータ)から書き手の感情状態や心的態度を多面的に推測する、テキストデータ解析の重要性はますます高まっている。本ワークショップでは、発表者らが開発した、テキストデータ解析のデファクト・スタンダードであるLIWC2015の日本語版(J-LIWC2015)について紹介する。ワークショップでは、Pythonによる日本語テキストデータの前処理の方法(MeCabを用いた形態素解析)や、分析の手順について解説を行う。また、データサイエンス領域での活用事例についても紹介する。参加にあたって特別な事前知識は必要としないが、前処理を行うにはコマンドラインでの操作にある程度慣れておく必要がある。また、前処理後の分析には英語版LIWC2015のソフトウェアが必要となるため、手元で分析を行いたい場合は各自で準備されたい。
注意事項
※参加には、日本心理学会第85回大会への参加申込が必要です。参加費等の詳細は第1号通信(PDF)をご参照ください。
※参加者の上限は100名です。
※チュートリアルでは、希望者にGoole Colabでの分析を行っていただく予定です。
※分析には、Goole Colabの開発環境(要Googleアカウント)、およびJ-LIWC2015の辞書ファイルが必要となります。
※J-LIWC2015の辞書ファイルは、LIWC2015ソフトウェア(英語版)のダウンロードサイトで配布しています。サイトの利用には、LIWC2015ソフトウェア(英語版)のライセンス(シリアル番号)が必要です。
※J-LIWC2015の論文はこちら
※J-LIWC2015のGitHubレポジトリはこちら